

Before my life as a Salesforce consultant, I used to install phone systems. One part of that job was running cable. If you’ve never seen cable being run before, it’s different than you’d think. There’s no magic process to get cable from point A to point B. The reality is, there’s a lot of trial and error, and most importantly, “tricks of the trade” used to make it happen. Some of these were quite unexpected, laughable, and also quite effective. For instance, would you ever imagine driving a remote control truck over a drop ceiling? Or Using fishing sinkers to drop a line down a concrete wall? All are very simple, yet effective ways to get the job done.
The same holds true for data manipulation in Salesforce. It takes a toolbox of options and processes to get something done. And sometimes, the simplest way to get something done isn’t the most obvious. What I’m going to show you are a few effective ways to solve some data challenges when you’re in a rush, don’t have a budget, and need to impress your boss.
Before I start, I need to say that there are some excellent data tools available on the AppExchange and we employ those often. Many use cases dictate the need for more robust tools than the process described below. This post is focused on the outliers, small loads or custom things, testing, or zero budget situations where work simply be done.
The use case – “I need to import a bunch of data. This data is dirty and does not have an External ID. I know this data has duplicates in it, and I need to get them removed before I insert a bunch of duplicate records”
FreeDupe Steps
- Define what is a duplicate by creating a duplicate match key
- Sort on duplicate match key
- Write a dupe flag formula
- Cleanup – Sort on said formula, paste values, and delete flagged duplicates
Define your Duplicates
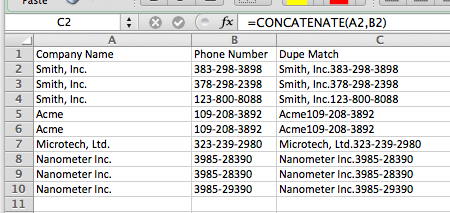
This is accomplished by establishing a “dupe match” key. As a simple example, if you are trying to dedupe on Company name, there may be many unique companies with the same name. However, deduping on company name + phone number will establish a unique combination for every set of records that should be inserted. Note that this could be expanded to contain additional or different fields, depending on the needs of your data operation. To create the text for the duplicate match key, use this formula:
=CONCATENATE(VALUE1,VALUE2)
The Concatenate function will string all the text values together. More information is available on the function here http://office.microsoft.com/en-us/excel-help/concatenate-HP005209020.aspx
Once the formula is written, fill it down to the bottom of the spreadsheet so every record now has a duplicate match formula.
Sort on Dupe Match Key
Let’s get all those dupes together. Select the column with the duplicate match formula. This can be done by clicking on the column “header” and then using the sort function to put them in order.
Write Dupe Flag Formula
This formula compares a value in the duplicate match key with the preceeding value. Since they are sorted, each duplicate group will have one value flagged as “Unique” and the rest will flag as duplicates.
Here is the basic formula:
=IF(C2 = C1,”Duplicate”,”Unique”)
Here’s what it looks like in action:

Cleaning Up
Finally, you want to actually remove those duplicate values. This has a few substeps:
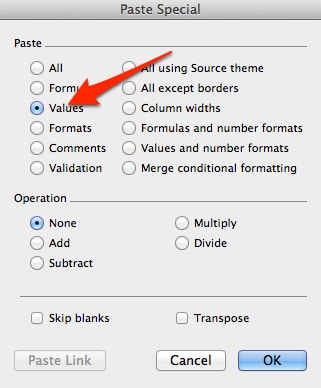
- Copy the column that contains the Duplicate formula results
- Paste Special to a new column. For the special dialogue box, select “Values”.
- Sort the new column ascending. Since you pasted “Values”, they will remain static.
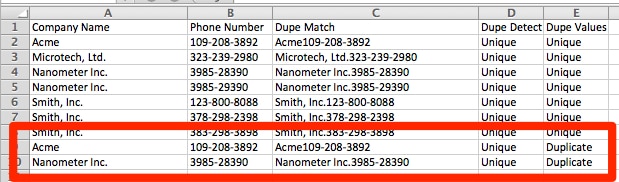
- Delete every record that has the word “Duplicate” in the field
- Now you’re left with the unique data as defined by your duplicate match rules.
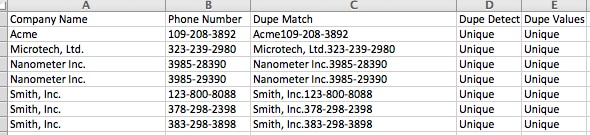
Congratulations, you’ve successfully deduped your data file. Review, import, and be merry! Do you have any tricks or tips you can add for this scenario, we’d love to hear them. Post a comment below!



